Cost Optimization for E-commerce Customer

One of our esteemed clients in e-commerce has been struggling with increasing cloud spend around USD 79k which keeps compounding month on month, before we took over. We analyzed their infrastructure thoroughly and came up with a list of options which have been exercised to bring down the cost.
We identified a set of applications on machines which need to be always running. We opted for the Compute Savings Plan in AWS where it will automatically bill your computing usage at reduced Savings Plans rates without paying any upfront fees. Through this, the customer was able to save ~21% of their existing spend, which is an immediate savings reflected on their next billing cycle.

The customer was using x86 processor-based machines for all applications. We suggested they use Graviton-based machines instead. Powered by ARM-based processors, Graviton instances typically come at a lower price point compared to x86 processors without any performance compromise. AWS also states they consume less power, which benefits AWS in the backend and encourages them to offer these at a lower cost. After ensuring all tools and automations were in place, we moved the applications one by one, helping the customer save around USD 3k per month.

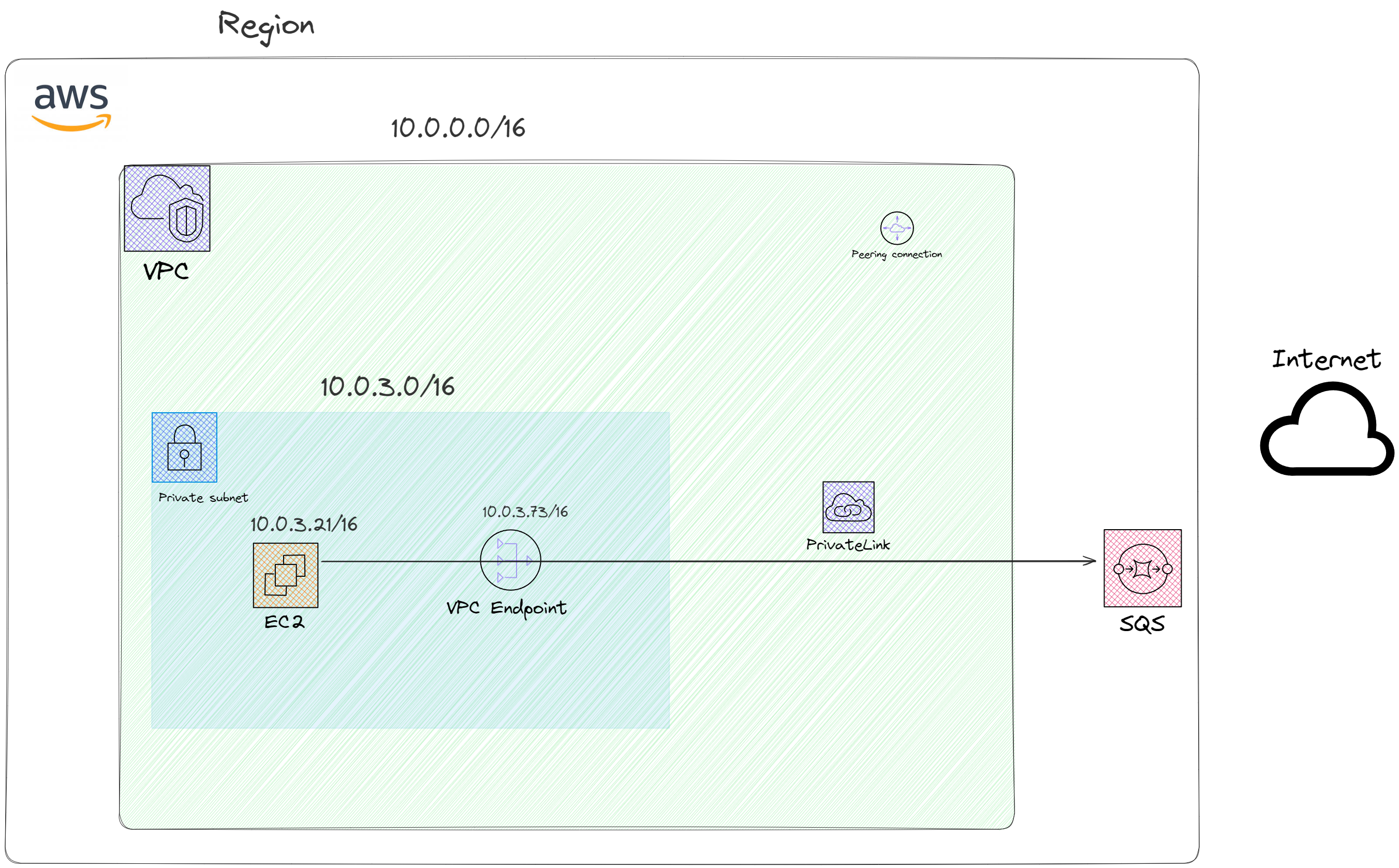
Some applications were using SQS Queues as a message queuing technique. We discovered the traffic flow and realized that pulling messages from queues was going through the internet instead of AWS Network. Every message being pulled through the internet increased bandwidth usage and cost. By configuring the VPC PrivateLink, applications hosted in EC2 and EKS now communicate to AWS SQS via AWS Network Backbone, saving around USD 5k per month.
The environment had many snapshots and AMIs taken regularly as backups, along with several hundred unattached volumes. With over 1500 AMIs and even more snapshots across regions, we developed a script and logic to regularly clean up unused and unnecessary snapshots, volumes, and AMIs.

We observed the e-commerce platform had region-specific traffic patterns, with peak traffic during the day and less traffic at night. We created schedules to run machines at optimal numbers during off-peak hours, adding additional machines during peak hours. This scheduling helped the customer save a lot of money.
We optimized scaling with schedules, but further improvements were needed. Applications run different components on EC2 machines and Kubernetes, such as query servers that utilize more memory. For consumer pods on K8s, we used Keda to scale based on the number of messages rather than CPU/memory.
For EC2, we developed an in-house tool to integrate with Prometheus and trigger events based on custom metrics, allowing appropriate scaling of EC2 Autoscaling Groups based on memory utilization and customer queries. This long-term optimization strategy saved money and avoided issues due to improper provisioning.
